수주내역 분석 프로그램
기계처럼 반복되는 업무를 프로그램화할 수 있는 것이야말로 개발자의 축복아닐까?
 찰리 채플린의 영화 《모던 타임즈》(1936)의 한 장면
찰리 채플린의 영화 《모던 타임즈》(1936)의 한 장면
발단
친구녀석은 전기업체를 다닌다. 해당 업체는 많은 사업을 수주하기 위해 나라장터1에 있는 과거 수주내역을 면밀히 분석하여 나름의 패턴(?)을 발견하였다! (예정가격사정률2이라는 정보를 활용하더라.. 자세한 건 비밀🤫)
하지만 이를 체계적으로 관리할 시스템의 부재로 소수점 아래 5자리까지의 큰 수들을 노트에 일일히 수기로 적어서 관리하고 있더라.
넌 개발자니까 쉽게 개선할 수 있잖아? (나를 자극해? 코딩으로 혼내주지👨💻)
전개
1. 카카오톡으로 소통
평일에는 각자의 일을 하고 있어 카카오톡으로 뜨문뜨문 소통했는데… Needs를 파악하기 힘들어서, 날을 잡아 Teams 회의를 진행했다.
2. Teams 회의
 개발자 유머 - 그네
개발자 유머 - 그네
아무래도 개발이 뭔지 생판모르는 비개발자와 소통하다보니 ‘우리가 서로 같은 내용을 말하고 있는가?’에 대한 걱정이 많았다.
혹여나, 당연하지만 빠진 요구사항이 있는지, 불편사항, 필요한 사항이 뭔지 꼬치꼬치 캐물어 요구사항을 상세화하였다.
또한 화면을 보면서 대화하는 편이 소통에 유리할 것 같아 빠르게 프로토타입을 만들어 피드백하기로 했다.
나는 실제 고객과 소통할 때는 90% 이상 기능이 구현된 화면을 보여주려 애쓴다. 불완전한 화면은 또 다른 파생 요구사항을 끊임없이 부른다고 생각하기 때문이다.
3. 회의 결과
- 데이터를 수집하는 기능이 필요했고,
- 수집한 데이터 중 필요한 데이터를 발라내어
- 계산 로직을 적용하여 정보로써 추출.
- 추출한 정보를 표출하고 저장하는 기능이 필요했다.
결과적으로 데이터 수집 및 분석에 용이한 python을 활용하여 개발해보기로 했다.
4. 프로세스 정립
 process flowchart
process flowchart
(1) GUI 실행
GUI 구성을 위한 파이썬 기본 패키지인 Tkinter를 커스텀한 customtkinter를 활용해봤다! (Tkinter는 그래픽이 올드했던 기억이 있어서…)
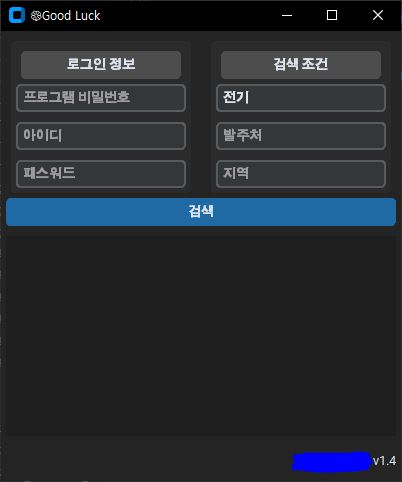 python program GUI
python program GUI
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def __init__(self):
super().__init__()
customtkinter.set_default_color_theme("blue")
customtkinter.set_appearance_mode("dark")
self.title("🍀Good Luck")
self.geometry("400x450")
self.resizable(width=True, height=False)
self.grid_columnconfigure((0, 1), weight=1)
self.grid_rowconfigure((6), weight=1)
#Login Info.
self.login_frame = MyLoginFrame(self, "로그인 정보")
self.login_frame.grid(row=0, column=0, padx=10, pady=(10, 0), sticky="nsew")
#Search Info.
self.parameter_frame = MyParameterFrame(self, "검색 조건")
self.parameter_frame.grid(row=0, column=1, padx=10, pady=(10, 0), sticky="nsew")
#Execute Button
self.button = customtkinter.CTkButton(self, text=INIT_BUTTON_TEXT, command=self.execute)
self.button.grid(row=4, column=0, padx=5, pady=5, sticky="ew", columnspan=3)
#Logging Textbox
self.textbox = customtkinter.CTkTextbox(self, width=400, corner_radius=0)
self.textbox.configure(state="disabled")
self.textbox.tag_config("ERROR", foreground="red")
self.textbox.tag_config("WARN", foreground="yellow")
self.textbox.grid(row=5, column=0, padx=5, pady=5, sticky="nsew", columnspan=3)
#Company + Version Info.
self.label = customtkinter.CTkLabel(
self, text=f"{COMPANY_NAME} {VERSION}", anchor="e"
)
self.label.grid(row=6, column=0, padx=5, pady=5, sticky="nsew", columnspan=3)
(2) 세션을 통해 조회조건에 맞는 데이터 목록 수집
로그인이 필요한 사이트로부터 데이터를 가져와야 했기에 세션정보를 활용할 수 있는 requests 모듈을 이용했고, 받아온 html을 파싱하기 위해 beautifulsoup4을 썼다. (python이 확실히 간편해서 좋드라~)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import requests
from bs4 import BeautifulSoup
...전략...
session = requests.session()
url = "" #service URL
data = {
"id": self.app.getParameter("id"), #아이디
"pw": self.app.getParameter("pw"), #패스워드
}
response = session.post(url, data)
soup = BeautifulSoup(response.text, "html.parser")
...후략...
(3) 수집한 데이터 목록 중 필요한 데이터만 추출 및 정제
비즈니스 로직이 담겨있어 글로만 설명하자면, 발주처/년도별로 조회해온 로우데이터는 시스템 성능을 위해 모두 .csv 파일로 저장해두었다. (올해년도는 제외)
 (sample)로우데이터 파일
(sample)로우데이터 파일
분석 과정에서는, 올해년도 외 로우데이터는 .csv 파일로부터 읽어오고 올해년도만 서버로부터 수집하도록 구현하였다. (서버 부하 방지를 위함)
(4) 읽은 데이터를 공식을 통해 분석 및 가공
로우데이터 샘플은 아래 표와 같습니다.
| 번호 | 공사번호 | 공사명 | 종목 | 발주처 | 지역 | 예정가격사정률 |
|---|---|---|---|---|---|---|
| 173 | AA | AA공사 | 토목/토건/전기 | XX관리단 | 전국 | -1.3715 |
| 172 | BB | BB공사 | 전기/전기(구매) | XX관리단 | 전국 | -2.16873 |
| 171 | CC | CC공사 | 전기 | XX관리단 | 전국 | -0.06006 |
| 170 | DD | DD공사 | 전기 | XX관리단 | 전국 | -0.50226 |
| 169 | EE | EE공사 | 전기 | XX관리단 | 경기 | -1.95256 |
로우데이터를 분석 및 가공하기 위해 pandas.DataFrame를 활용하였습니다.
- 발주처 / 년도별 로우데이터를 읽어옵니다.
- 예정가격사정률에 있는 결측치를 제거합니다.
- 종목과 지역으로 필터링합니다.
- 예정가격사정률에 100을 더합니다.
- 소수점 1자리까지 같은 수들을 그룹핑합니다.
- 년도별 데이터를 모두 병합하고, 기준에 맞게 정렬합니다.
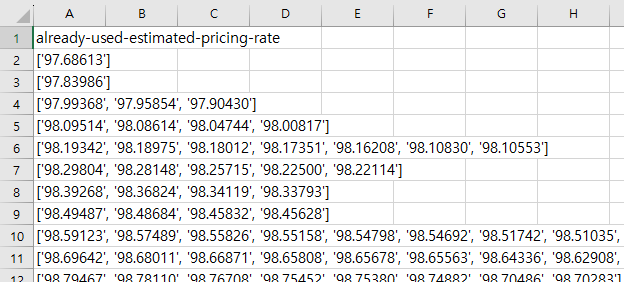 (sample)분석 결과 정보
(sample)분석 결과 정보
(5) 가공된 정보 표출 및 저장
결과 파일을 .csv파일로 저장하고 Notepad로 Open합니다. subprocess를 활용합니다.
1
2
3
4
5
# Notepad로 열기
def openCSV(self, fileName):
filePath = self.__getFilePath(fileName, True)
self.app.appendLog(f"Result File Open: {filePath}")
subprocess.run(["notepad.exe", filePath])
위기 & 절정
1. 인코딩 이슈
엑셀에서 인코딩이 UTF-8인 csv파일을 읽으면 한글이 깨지는 것을 알고 계신가요?
때문에 파일 I/O 시에, default encoding을 ANSI로 하도록 소스를 수정하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# CSV 쓰기
def toCSV(self, data, fileName, isResult=False):
filePath = self.__getFilePath(fileName, isResult)
df = DataFrame(data) # converting to DataFrame
df.to_csv(
filePath, # file path, file name
sep=",", # seperator, delimiter (구분자)
na_rep="NaN", # missing data representation (결측값 표기)
encoding="ANSI",
index=False,
)
# CSV 읽기
def readCSV(self, fileName):
isResult = False
filePath = self.__getFilePath(fileName, isResult)
csv = pd.read_csv(
filePath,
usecols=["part", "local", "estimatedPricingRate"],
encoding="ANSI"
)
return csv
엑셀에서 CSV 파일 읽을 때 한글 깨지는 현상 해결 방법도 있으니 참고바랍니다.
2. 소수점 이슈
float 연산 시 부동소수점 이슈가 있었다!
소수점 연산을 하다보니 부동 소수점 산술: 문제점 및 한계가 있었다.
1
2
3
4
5
6
# 부동소수점 산술의 문제점
# - 불행히도, 대부분의 십진 소수는 정확하게 이진 소수로 표현될 수 없습니다.
# - 결과적으로, 일반적으로 입력하는 십진 부동 소수점 숫자가 실제로 기계에 저장될 때는 이진 부동 소수점 수로 근사 될 뿐입니다.
0.1 * 3 == 0.3 # False
1.2 - 0.1 == 1.1 # False
0.1 * 0.1 == 0.01 # False
일단 아래와 같이 소수점 아래 5자리까지만 표현되도록 포맷팅을 통해 해결하였다. (완벽한 해결책은 아닌 것 같다…)
1
2
3
4
5
6
# added: 예정가격사정률에 100을 더한 수
# group: grouping을 위한 수(added를 소수점 1자리까지 내림)
filteredResults = filteredResults.assign(
added=lambda x: (x["estimatedPricingRate"] + 100).apply(lambda f: "{:.5f}".format(f)),
group=lambda x: ((x["estimatedPricingRate"] + 100) * 10).apply(np.floor) / 10,
)
3. NO-DATA 이슈
서버로부터 조회 시, 로우데이터가 아예 0건인 경우가 있었다!
분석 과정 전에 결측치를 제거하는 로직이 있기에 문제가 없을 것으로 예상했으나, 검색결과가 없는 년도의 로우데이터 파일이 생성되지 않아 분석 과정에서 예외사항이 발생하고 있었다.
- 분석 영역에서 없는 파일은 넘어가도록 분기하여 개선할까?
- 아니면 수집 영역에서 데이터가 없는 로우를 저장하도록 할까?
고민하다가 분석보단 수집에서 처리하는 것이 역할에 맞다고 판단해서, 모든 컬럼이 None인 로우 1건을 저장하도록 처리하였다. (로우데이터가 없음을 알아채기에도 좋아보였다.)
1
2
3
4
5
6
7
8
9
results.append({
"no": None, # 번호(no)
"constructionNo": None, # 공사번호(constructionNo)
"constructionName": None, # 공사명(constructionName)
"part": None, # 종목(part)
"owner": None, # 발주처(owner)
"local": None, # 지역(local)
"estimatedPricingRate": None, # 예정가격사정률(estimatedPricingRate)
})
4. 파일명 이슈
파일명에
/가 들어간 경우에 파일 I/O에 실패했다!
파일명에 /가 포함되는 경우가 존재했다. 파일에서 /는 경로(path)를 뜻하기 때문에 저장에 실패한 것이다. 고로 파일명에 포함된 /를 &로 변환하여 저장할 수 있도록 로직을 개선하였다.
1
2
3
4
# File Path 얻기
def __getFilePath(self, fileName, isResult=False):
replacedFileName = fileName.replace("/", "&")
return f"{RESULT_PATH if isResult is True else DATA_PATH}/{replacedFileName}.csv"
5. 고대유물 이슈
아직도 windows 8에 엑셀 2007을 쓰고 있다고..!?😱😱😱😱🤪
고대유물을 쓰고 있는 내 친구… (혹시 박물관에서 일하는걸까?) 시스템 성능(메모리)을 고민하지 않을 수 없었다.
1
2
# del 활용
del [[dfs, dfs1, dfs2]]
1
2
3
4
5
6
# usecols 활용
csv = pd.read_csv(
filePath,
usecols=["part", "local", "estimatedPricingRate"],
encoding="ANSI"
)
결말
여러 페이지에 걸쳐 조회하고 일일히 수기로 계산해야 했던 과거와 달리, 30분은 족히 걸릴 일이 1분만에 해결된다고 고맙다고 하더라😃
업무가 (30min - 1min) / 1min = 2900% 개선되었다!
나도 덕분에 python도 써보고 skill-up할 수 있어 재미있고 뿌듯했다. 개발자는 이 맛이지!
나는 새로운 언어에 도전하는 것에 큰 거부감이 없다. 개발 언어끼리는 유사한 점이 많다고 생각하기 때문이다. 요즘은 실무에서 SAP사가 제공하는 ABAP이라는 언어를 써보고 있는데 디버거가 잘되어 있더라.
(근데 영어는 잘 못하겠어🤣)
프로젝트 정보
python 라이브러리 목록
GUI
customtkinter: GUI 구성pyinstaller: exe파일 생성
데이터 수집
requests: HTTP 요청beautifulsoup4: HTML 구조 파악
데이터 정제 및 분석
pandas: 데이터 처리 및 분석
버전 및 수정내용
| 버전 | 일자 | 수정내용 |
|---|---|---|
| v1.0 | 2023.12.12 | 최초 배포 |
| v1.1 | 2023.12.12 | 엑셀 한글 깨짐 개선, 소수점 자리수가 넘어가는 Bug fix |
| v1.2 | 2023.12.13 | 엑셀로 열 때 encoding ANSI로 변경. |
| v1.3 | 2023.12.13 | 데이터가 없는 경우 예외 처리. |
| v1.4 | 2023.12.21 | 파일경로에 /가 들어가는 경우 &로 대체하도록 함. |